Home
Services
Data Studio as a Service
Data Science as a Service
Data Infrastructure as a Service
Data Science Advisory Services
Risk Assessments
Data Science Education
DSaaS
Why DSaaS?
What is Data Science?
What is DSaaS?
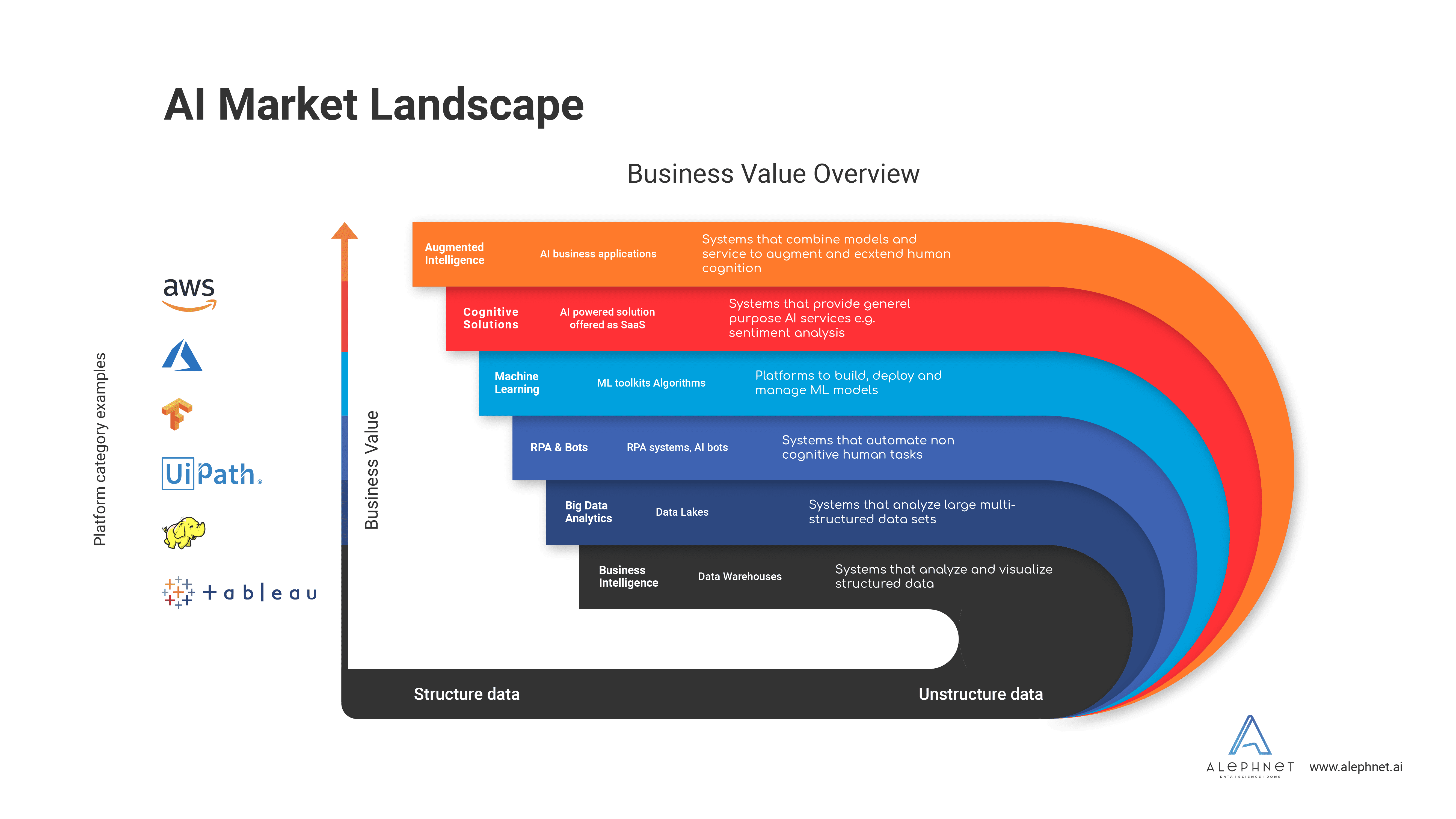
AI Landscape?
System of Insights?
Solutions
Partnership
About Us
Contact Us
Jobs
Select Page
ai landscape
Search
Search for:
Recent Posts
How Cognitive Search Helps Companies Elevate Performance
Data science and the geometry of changing beliefs
Recent Comments

Recent Comments